
Building A Secure, Resilient, and Rapid File-Sharing System
June 1st 2024
I picked up network programming this semester, and it has been a blast. Ever since I started playing with computers, I have been fascinated with how they communicate with each other, and finding out how the internet works has been a dream of mine. In CS453, HTTPs, TCPs, RDTs, DHCP, and all the likes were made all the more interesting with packet sniffing softwares and simulated excercises. The course has been the most demanding at UMass so far, yet the most worthwhile (so thanks Arun!).This project all started with a simple question: how can we transfer files securely and rapidly over the internet? The answer is not as simple as it seems, as we have to consider many factors, including the reliability of the connection, the security of the data, and the speed of the transfer. In this blog post, we will delve into different implementations of a file-sharing system, and discuss the pros and cons of each approach. We will also explore the backbone of the systems, including the TCP and UDP protocols, and the different ways to secure the data. The source code of this project can be found in two different repositories: umass-cs453 and cs453-proj2.
A High-level overview of file-sharing systems
In the first part of the project, we try to understand the different ways to transfer files over the internet. The goal is to achieve a transmission time of 48 seconds for a 800 kB file. By using multithreading and memory buffer, I was able to reduce this time to 36 seconds. This matches the best run time given by the solution, and was the best one among 50 students of the class.
Client Server and Peer To Peer file sharing
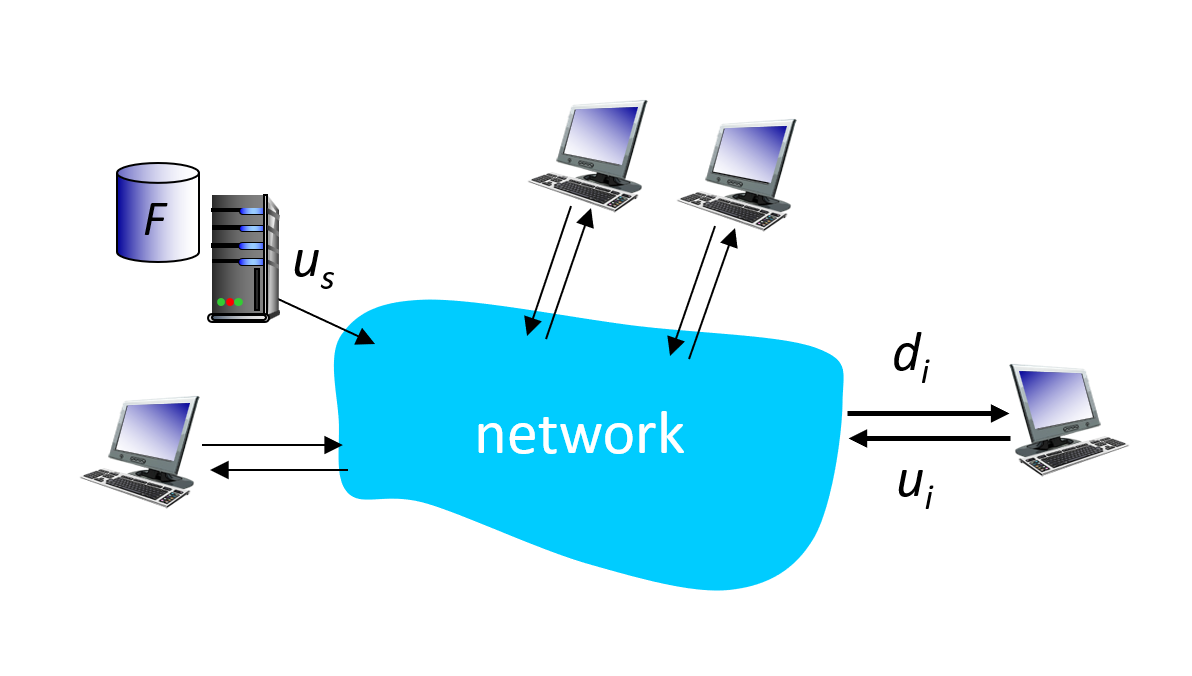
Unlike the client server model, where each client will get served by the listening server, the peer to peer file sharing model takes advantage of the cumulative power of the peers. If a file is of size \[F\] bytes is to be distributed to \[N\] clients, the server upload rate is $u_s$ and the min client download rate is $d_{min}$ then in Client-Server model, it will take: $$D_{CS} = \max\{NF/u_s,F/d_{min}\} $$ Meanwhile, the P2P model improves this by only making the server tranmit the file once, resulting in a delay of $F/u_s$ rather than $NF/u_s$. Meanwhile, the cumulative time of upload is $$NF/(u_s + \sum u_i) \approxeq NF/Nu_i \approxeq F/min(u_i)$$ Therefore, when $N$ is very large and $d_{min}$ is acceptable, the expected time of file transfer is: $$D_{P2P} = \max\{F/u_s,F/d_{min},NF/(u_s + \sum u_i)\} \ll D_{CS}$$
Multi-threading
Data chunks are requested via TCP, so loss and corruption is already handled by the packages.Because the server is rate-limited, multi-threading will not work on Client-Server model. However, on the Peer-To-Peer model, we can create one thread for each peer, and concurrently request for data.
Because each user may only establish 5 connections to peers (who are actually different randomized ports of the same server), the first idea was to divide the chunks into modulo 5: the first peer to handle chunks number $0, 5, 10,...$ ; the second to handle chunks $1, 6, 9,...$ ; and so on. This solution would give approximately 48 seconds average run time, but it was not good enough for the leaderboard.
The second idea is to store the latest unhandled file as a variable, and then use a semaphore / mutex to capture and update the variable every time a thread is free. This is better because the channel is noisy, so some threads will just finish first and stay idle, while some other threads struggles to download a few chunks. So having the good channels do more work significantly smoothen the downloading process.
Peer discovering
One problem of the Peer To Peer file sharing is peers churning from the network once it has received what it needed. (and we won't know when). So it is important to keep the information about which peer remains active, and find a replacement when one of our favorites churn from the network.And just like that we have a file-sharing system that is secure, resilient, and rapid.
Transmission Control Protocol (TCP) with GBN and Dynamic RTO
The second part of the project requires a fast and resilient implementation of the Transmission Control Protocol (TCP). Unlike the first project, there is no time limit for the second project, except Gradescope runtime limit. Howver, accuracy will be heavily evaluated using 16 tests of incrementing difficulty and noisy levels, with corruption rate $>0.5$ for the last few tests. The real numbers were not disclosed. By using the Go-Back-N (GBN) protocol and dynamically adjusting the Recovery Time Objective (RTO), I again achieved the best score of the class (the first time was in cs453-project1). Kudos to my fellow teammate Sagarika! For UMass students: Winning these minicontests comes with a generous amount of extra credit as well!
For UMass students: Winning these minicontests comes with a generous amount of extra credit as well!
Reliable Data Transfer Overview
Unlike the UDP protocol wherein the sender blasts datagrams at the receiver, RDT protocols requires the data to be received in an appropriate order. This is challenging in the setting of noisy networks with possibility of losses and corruptions.In the case of network corruption, it is important to have a way to acknowledge the reception of accurate information. This is achieved through ACK/NAK. An ACK is sent in the event of not corrupted message, and a NAK otherwise. NAK, however, is not required, as the recipient can simply acknowledge the sequence number of the next anticipated packet. In this project I provide a NAK-free implementation.
In the case of losses, the recipient may never receive the message at all. Therefore, the sender must somehow be able to detect a loss event. This is achievable through timeouts. If the sender does not receive a respond from the receiver after a time $T$, it assumes that a loss has occured, and resends the message.
The transmission protocol can be represented as the following Finite State Machine of RDT 2.2. Note that there are multiple layers to Reliable Data Transfer, which are listed here
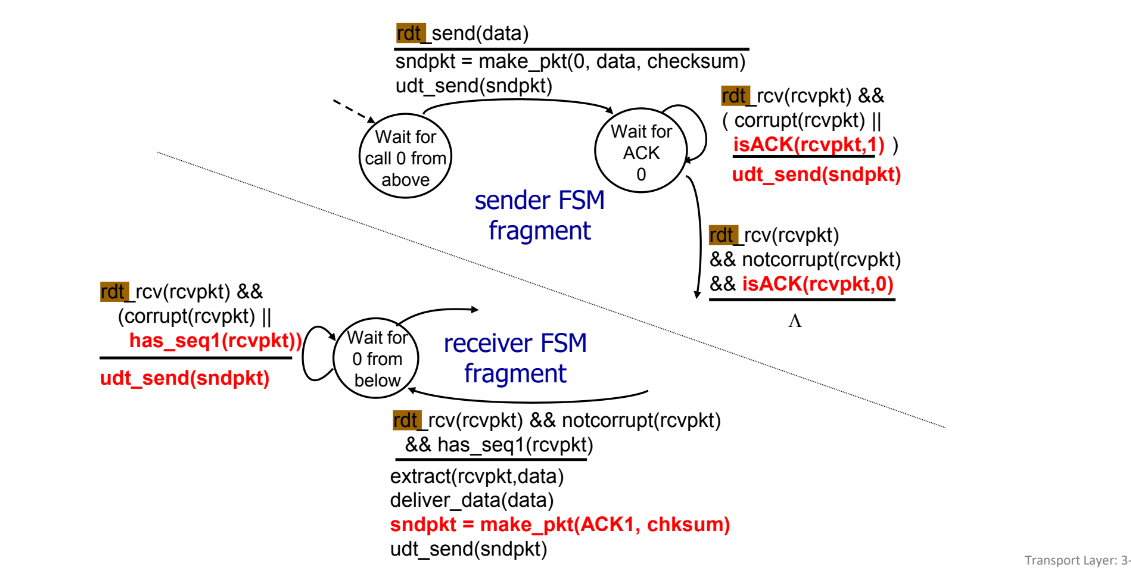
Pipelining using GBN
In the Finite State Machine given above, message sequence numbers can increment gradually. However, there is no pipelining to this procedure. (i.e. packet will not be sent unless the previous packet has been ACKed and the ACK is successfully received.)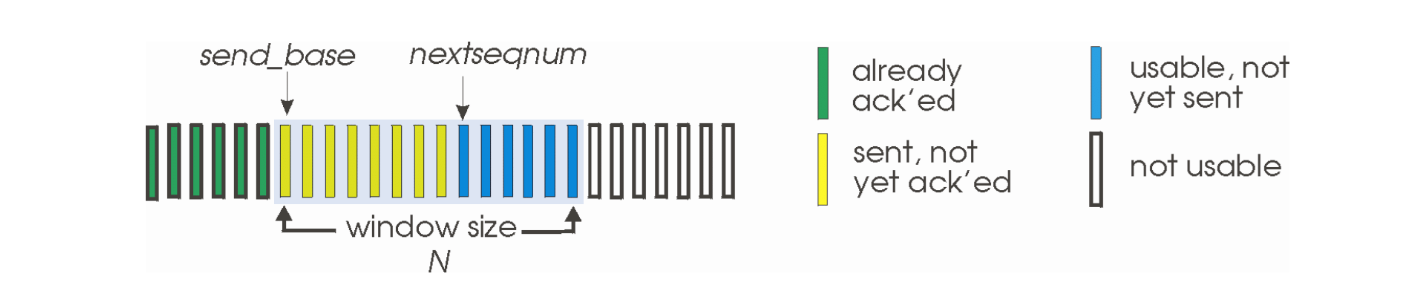 This can be modified by using the Go-Back-N Protocol.
In the GBN protocol, the sender sends N continguous data chunks to the receiver.
When the receiver have ACKed all data chunks up to index $i$,
the sender will continue to send $n+1, n+2, \cdots, n+i$.
However, if at any point a packet $j$ timeouts (convince yourself that this is also the earliest un-ACKed packet),
then it will resend all packets $j, j+1, \cdots, j+n-1$, hence the name Go-Back-N.
This can be modified by using the Go-Back-N Protocol.
In the GBN protocol, the sender sends N continguous data chunks to the receiver.
When the receiver have ACKed all data chunks up to index $i$,
the sender will continue to send $n+1, n+2, \cdots, n+i$.
However, if at any point a packet $j$ timeouts (convince yourself that this is also the earliest un-ACKed packet),
then it will resend all packets $j, j+1, \cdots, j+n-1$, hence the name Go-Back-N.
TCP Congestion Control
Another feature is of RDT is timeout. It is important to have a timeout algorithm that takes into account the current network status rather than a hard-coded value. We use the algorithm specified in RFC 6298 to calculate the retransmission time. To compute the current RTO, given the most recent round trip time $R'$, we calculate the smoothed current round trip time using Exponential Moving Average $$SRTT = (1-\alpha)*SRTT + \alpha R'$$ and the variance of the round trip time is given by: $$VAR = (1 - \beta) * VAR + \beta * |SRTT - R'|$$ choosing $\alpha = 0.125, \beta = 0.25$, and let $G$ be the clock granularity of the network, RTO is given by: $$RTO = SRTT + \max (G, 4*RTTVAR)$$ In the event of a loss, RTO is doubled and capped at 6 seconds (as opposed to 60 seconds in RFC 6298). $$RTO = \min(6, 2*RTO)$$Suggested Improvements
An alternative to the Go-Back-N protocol is the Selective Repeat protocol, which only resends the lost packets rather than all packets after the lost packet. This is more efficient, but also more complex to implement. During my research, I realized that the Go-Back-N protocol is more than sufficient for the scope of this project. It is also employed in the real TCP protocol, so it was a good exercise to understand it.Another improvement is to implement a more sophisticated congestion control algorithm, such as the TCP Tahoe or TCP Reno algorithms. These algorithms are more robust in handling congestion in the network, and can achieve higher throughput and lower latency.
Lastly, one may think about using multi-threading to handle multiple connections at once, which can further improve the speed of the file transfer.
References
-
UMass CS453
- dmtrung14-courses/umass-cs453
- dmtrung14-courses/cs453-proj2/
- Wikipedia.org - Finite State Machine
- geeksforgeeks - Principles of Reliable Data Transfer Protocol
- RFC 6298
- geeksforgeeks - Reliable Data Transfer RDT 2.2
- geeksforgeeks - Mutex vs Semaphore
- Wikipedia.org - Acknowledgement (data networks)